If there's one thing supercomputing enthusiasts appreciate as much as raw processing power, it's achieving more with less memory. Researchers at Tokyo Metropolitan University have made a promising advancement by reimagining the Lattice-Boltzmann Method (LBM), a workhorse in computational fluid dynamics, which significantly reduces memory requirements while maintaining accuracy and stability.
Why This Matters to Supercomputing
Fluid and heat flow simulations, from modeling airflow over aircraft wings to predicting climate patterns and even simulating blood flow in biomedical research, are classic examples of problems that push supercomputers hard. These simulations partition a physical domain into millions, or even billions, of grid points. At each point, the Lattice-Boltzmann Method (LBM) tracks the distributions of particle “parcels” as they move and collide across the grid to compute phenomena such as velocity and temperature.
However, there's a catch: storing additional information at each grid point significantly increases memory usage. In large-scale HPC environments, memory is a valuable resource. Memory costs, both financially and in terms of energy, can restrict the scale, resolution, and duration of simulations. This is where the new algorithm truly excels.
The Innovation: Low-Memory LBM
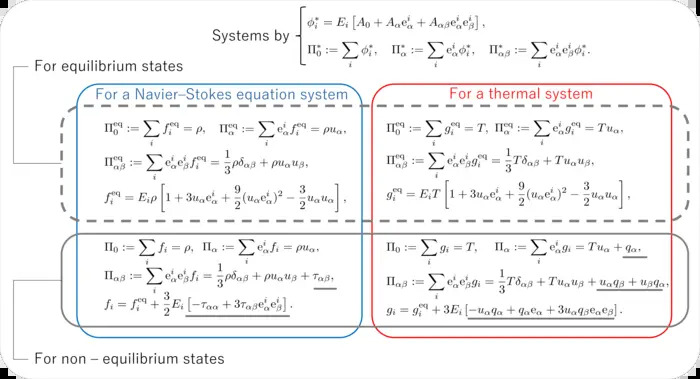
Associate Professor Toshio Tagawa and doctoral student Yoshitaka Mochizuki redesigned the LBM, incorporating a clever trick: they added small "optional moments" that implicitly encode gradient information, essentially, telling the algorithm how values change from point to point without needing to store all that data explicitly. Because gradients are built into the formulation, the simulation doesn’t have to keep huge sets of intermediate variables in memory.
In tests across multiple fluid and heat flow benchmarks, the new method slashed memory usage by roughly 50% in certain scenarios, which is enormous in HPC terms. If a simulation previously just barely fit into a supercomputer’s memory, this approach could make it comfortably fit or allow it to run at a much higher resolution.
Why Supercomputers Will Care
Supercomputers are extremely parallel machines, but they still contend with finite memory per node, per core, and per job. Reducing memory footprints can:
- Enable larger, more detailed simulations without needing bigger machines.
- Lower energy use (memory operations are a significant power draw).
- Improve scalability by reducing communication overhead tied to data shuffling.
In practice, this algorithmic advance can influence how developers optimize code for systems and next-generation HPC architectures. Memory constraints are a major bottleneck in fluid and heat simulations, particularly in 3D, multiphysics, or long-duration runs. The new low-memory LBM addresses this challenge.
Wide Relevance Beyond Academia
The innovation isn’t just for textbook problems. LBM and similar lattice-based schemes are used in:
- Aerospace and automotive design
- Weather and climate modeling
- Porous media flow (e.g., oil reservoir simulation)
- Biomedical simulations (e.g., capillary networks)
Any domain where fluid or heat behavior matters at scale and where HPC resources are stretched thin could benefit.
Computational Insight, Not Just Raw Power
It’s always tempting in supercomputing to chase more cores, more flops, or bigger clusters. But advances like this remind us that algorithmic ingenuity often beats brute force. Memory efficiency isn’t just a nice-to-have; it’s a multiplier that lets existing systems do far more with what they already have.
As future systems come online, low-memory formulations like this will be an important part of the HPC playbook. They help supercomputers push into previously unreachable problem sizes, enabling science, engineering, and industry to ask bigger questions and get answers faster.
In the world of supercomputing, sometimes less memory used means more science done, and that’s worth celebrating.