

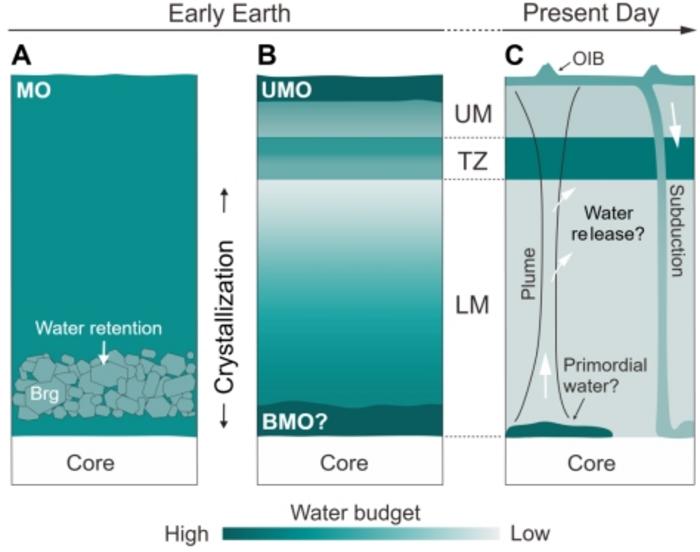
A high-profile Science paper and its accompanying press release from the Chinese Academy of Sciences make a bold claim: Earth may have locked away massive amounts of water deep in its mantle during the first tens of millions of years after formation, thanks to the mineral bridgmanite acting like a high-pressure “water container.” This challenges decades of textbook assumptions about a desiccated early mantle and a late veneer of water delivery.
Before we award supercomputing a gold star, it's important to consider whether the computational methods and modeling used are sufficiently transparent and if this impactful result truly relies on the world's fastest machines or primarily on traditional laboratory and theoretical calculations.
The press release highlights experimental setups, such as diamond anvil cells with laser heating and ultra-high-pressure imaging tools, used to replicate conditions at depths greater than 660 km below Earth’s surface. These are physical simulators of pressure and temperature, not digital ones.
However, nearly every Science paper on deep Earth processes, including this one, relies on numerical models to extrapolate limited lab data to planetary scales.
Here's the catch: The team doesn't clearly explain whether or how high-performance computing (HPC) or supercomputing simulations were used in their work. The Science article's abstract and press summary focus on experiments and analytical techniques for measuring microscopic water content, and Science's DOI listing confirms the publication details but makes no explicit mention of HPC resources.
That's somewhat unusual given the claim of planetary-scale simulations. Typically, understanding Earth's thermal and compositional evolution necessitates 3D models of mantle convection, phase transitions under extreme pressure, and coupled multiphysics, all tasks well-suited for supercomputers. However, the publicly available summary of this study doesn't detail such modeling or reference specific HPC centers or computational frameworks.
In Earth and planetary sciences, HPC integration is standard when scaling lab data to global processes. Papers in other fields explicitly link computational results to HPC resources and acknowledge the supercomputers used for simulations. However, this study's press release and the public Science abstract fail to cite any computing facility or discuss numerical simulation workflows, and Science's repository entry doesn't list HPC under methods. This creates a notable gap between the claim of "vast water storage deep in the mantle" and the evidence that supercomputing played a central role in the research.
This differs from genuinely computation-heavy studies in Science and similar journals, where authors provide details on the supercomputers used, parallel codes, numerical solvers, grid resolution, and performance scaling metrics, the essential elements of reproducible computational science. The lack of this technical information here raises questions about how significantly this result advanced beyond analytical theory and high-pressure experiments.
It's possible the researchers used computational models behind the scenes, perhaps calibrating thermodynamic or kinetic models with HPC simulations, but such details may be hidden in supplementary materials not yet public. However, based on the press materials and abstract, readers are left to guess whether this research is experimental geochemistry complemented by modest numerical modeling, or truly HPC-driven planetary challenge computing.
Why does this matter? The frontier of Earth science increasingly intersects with supercomputing. Massive datasets from seismic tomography, petrological phase diagrams, and global geodynamic simulations all depend on HPC to turn physics into planetary predictions. In an era when AI and HPC are reshaping scientific discovery, expanding what is novel and highly cited across fields (see broader analyses of HPC’s impact on research output and novelty), transparency about computational methods is not an optional extra; it is central to confidence in the claims.
The idea that Earth's deep interior may have sequestered oceans' worth of water is fascinating and potentially paradigm-shifting. However, until the computational underpinnings are clearly described, it is premature to celebrate this as a triumph of supercomputing. In an age when HPC is often the invisible engine of scientific breakthroughs, clarity about its role is not a luxury; it's a requirement for trust.
Supercomputing may yet prove essential for modeling Earth's earliest conditions at scale, but based on the available summaries of this work, we are not there yet.

