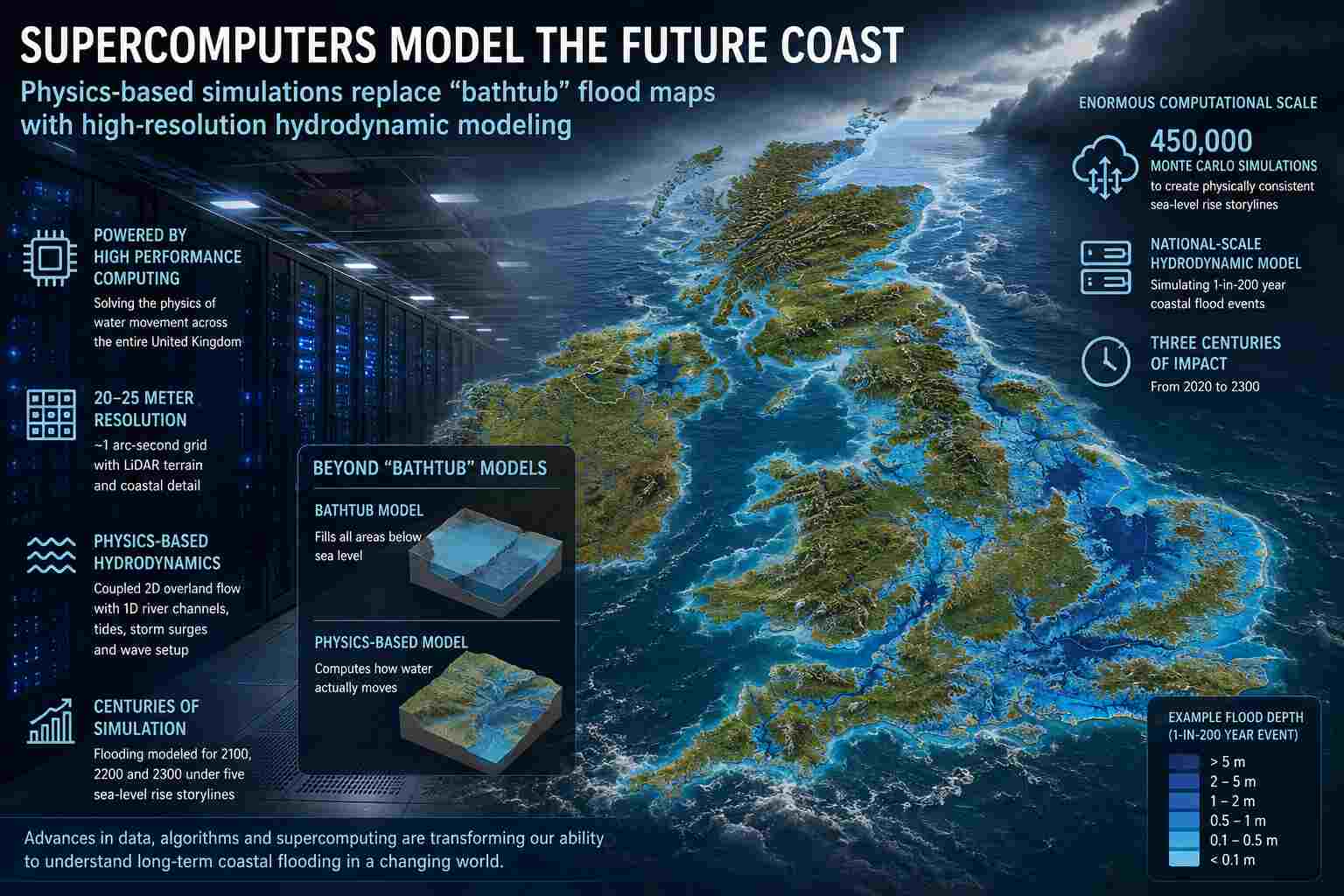
National-scale hydrodynamic simulations reveal how advances in high-performance computing are transforming centuries-long coastal flood forecasting.
For decades, global coastal flood projections have relied on the simplifying assumption that any land below projected sea level will naturally flood. Researchers often term these "bathtub models" because they treat the landscape as a basin being filled with water. However, a new study published in Nature Communications signals a shift toward far more sophisticated methodologies.
By leveraging advances in high-performance computing (HPC), researchers have developed a physics-based simulation capable of modeling coastal flooding across the entire United Kingdom at an unprecedented spatial resolution, with projections extending three centuries into the future. Ultimately, this research highlights how modern supercomputing has fundamentally expanded the computational boundaries of environmental simulation.
Computing the movement of water
The computational challenge facing flood modelers is enormous.
Water does not simply spread evenly across landscapes. It accelerates, slows, changes direction, interacts with rivers, follows terrain, overtops barriers, and responds dynamically to tides and storm surges. Capturing these processes requires solving the shallow-water equations across millions of computational cells while simultaneously modeling river networks and coastal boundaries.
Only recently have advances in numerical methods, high-resolution terrain datasets, and HPC resources made these simulations practical on national scales. As the authors explain, improvements in numerical schemes and High Performance Computing now allow hydrodynamic flood modeling to be applied at scales ranging from national to global, something that was previously impractical. Instead of assuming every low-lying area floods, the new model computes where water can physically travel, how quickly it moves, and how hydraulic connectivity influences inundation.
Building a digital twin of the United Kingdom
At the heart of the study is one of the most sophisticated national flood models yet constructed.
The researchers simulate the entire United Kingdom using a coupled hydrodynamic model operating at approximately 20–25-meter spatial resolution. The system combines two-dimensional shallow-water flow across floodplains with one-dimensional river channel simulations, allowing rivers of every size to interact realistically with coastal flooding.
Terrain elevations are derived primarily from airborne LiDAR surveys with approximately 10-centimeter vertical accuracy, while river geometries, coastal boundaries, storm surge profiles, tidal cycles, and wave setup are incorporated into a unified computational framework.
The result is effectively a high-resolution digital twin of Britain’s coastline capable of responding dynamically to changing sea levels and extreme coastal events.
Millions of calculations before the flooding even begins
The flood simulations represent only one stage of the computational workflow.
Before any water is modeled, the research constructs physically consistent sea-level rise storylines from 450,000 Monte Carlo simulations for each emissions scenario. These simulations combine multiple interacting components, including:
- Ocean thermal expansion
- Antarctic ice-sheet loss
- Greenland ice-sheet melt
- Mountain glacier contributions
- Land-water storage changes
Researchers then filter these enormous ensembles to identify internally consistent future trajectories before coupling them into the hydrodynamic flood simulations.
This layered modeling strategy highlights how modern environmental science increasingly depends on large ensembles and computational statistics long before the primary physical simulations begin.
From static maps to dynamic physics
Traditional flood maps often assume that any land below a projected water elevation becomes inundated.
The authors argue this approach can substantially overestimate flooding because it ignores hydraulic connectivity and the actual physics governing water movement.
Their hydrodynamic approach instead solves the governing equations of fluid motion, enabling simulations that account for terrain, river channels, coastal geometry, tides, storm surges, and evolving water depths throughout an event.
The difference is analogous to replacing a static elevation map with a fully interactive fluid simulation.
For engineers, planners, and emergency managers, that distinction can significantly improve confidence in identifying which infrastructure is genuinely vulnerable.
Simulating centuries instead of storms
The study explores flooding under five physically consistent sea-level storylines extending through the years 2100, 2200, and 2300.
Each scenario requires repeated national-scale hydrodynamic simulations based on 1-in-200-year coastal storm events, allowing researchers to examine how changing boundary conditions alter flood behavior over centuries rather than days.
While the scientific conclusions concern long-term coastal exposure, the computational achievement is equally notable: running repeated high-resolution simulations across an entire nation using physically based hydrodynamics.
A broader trend in scientific computing
Flood modeling joins an expanding list of scientific disciplines transforming HPC.
Fields ranging from molecular dynamics and astrophysics to weather forecasting and materials science have increasingly abandoned simplified approximations in favor of direct numerical simulation as computational resources have expanded.
This study illustrates that coastal science is following the same trajectory.
Instead of asking where water might accumulate based solely on elevation, researchers can now simulate how water actually behaves.
That shift produces richer scientific insight while creating more realistic digital representations of complex natural systems.
Supercomputing as the enabling technology
Perhaps the paper’s most important contribution to computational science is not any individual flood projection but the demonstration that national-scale, physics-based environmental digital twins have become practical.
The authors explicitly acknowledge that advances in high performance computing were instrumental in making these simulations possible.
As exaflops supercomputing matures and increasingly detailed terrain datasets become available worldwide, similar computational frameworks could eventually model coastlines across entire continents with greater spatial resolution, larger ensembles, and more comprehensive representations of physical processes.
For the HPC community, that represents the real story.
The future of flood prediction is no longer built on filling digital bathtubs, it is built on solving the equations of motion across millions of grid cells, transforming coastlines into living computational systems that evolve under the laws of physics.