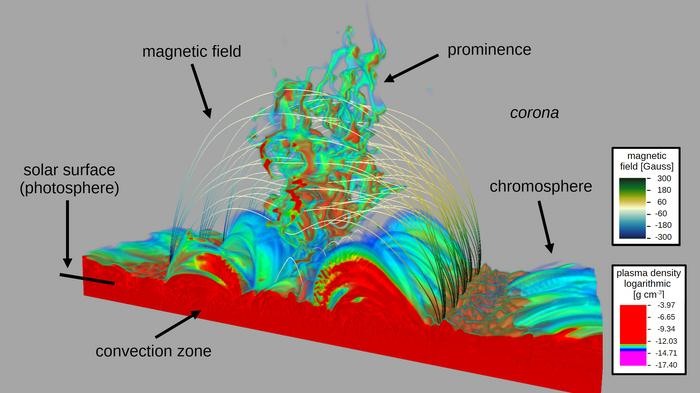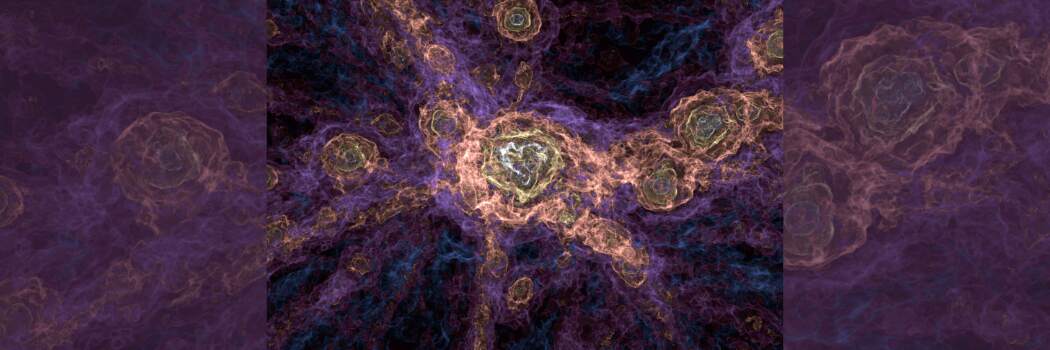
Marking a significant advancement in computational astrophysics, researchers at Durham University have released one of the most extensive cosmological simulation datasets to date. This comprehensive digital reconstruction of the Universe, enabled by high-performance supercomputing, demonstrates the unprecedented scale at which modern astrophysical phenomena can be modeled and analyzed.
Central to this achievement is the FLAMINGO project, an international collaborative effort aimed at simulating the evolution of matter across cosmological timescales. The resulting dataset, exceeding 2.5 petabytes, a volume comparable to approximately half a million high-definition films, provides the global scientific community with access to highly detailed virtual universes that trace the formation and evolution of cosmic structures from the post-Big Bang epoch to the present era.
Supercomputing as the engine of discovery
The simulations were executed on the COSMA-8 supercomputer, part of the UK’s DiRAC national high-performance computing infrastructure. This system, purpose-built for data-intensive cosmological workloads, enabled the integration of vast spatial scales with sophisticated physical modeling.
Unlike earlier generations of cosmological simulations, which often forced a trade-off between resolution and scale, FLAMINGO bridges both extremes. It simultaneously models:
- Gigaparsec-scale cosmic volumes, spanning billions of light-years
- Galaxy formation physics, including gas dynamics, star formation, and feedback processes
- Dark matter and dark energy evolution, the dominant drivers of cosmic structure
- Large-scale clustering, producing the filamentary “cosmic web” observed in galaxy surveys
This dual capability reflects a fundamental shift enabled by supercomputing: the convergence of astrophysical detail with cosmological precision.
The computational architecture of a universe
From a technical standpoint, the FLAMINGO simulations represent a triumph of parallel computing and algorithmic design. The underlying software stack, built around advanced cosmological simulation codes such as SWIFT, leverages:
- Massively parallel processing, distributing billions of computational elements across thousands of cores
- Hybrid gravity–hydrodynamics solvers, capturing both collisionless dark matter and baryonic physics
- Time-resolved evolution, tracking the growth of structure across cosmic epochs
- Petascale I/O pipelines, capable of writing, storing, and indexing multi-petabyte outputs
These simulations follow matter as it collapses under gravity, forming halos, galaxies, and clusters, while simultaneously modeling the energetic feedback from stars and black holes that regulates galaxy growth. The result is a statistically robust, physically grounded synthetic universe.
Crucially, the dataset’s size and complexity required not only raw compute power but also innovations in data accessibility. The team developed a web-based platform that allows researchers to query and extract subsets of the data without downloading entire petabyte-scale files, effectively democratizing access to supercomputer-scale science.
A global resource for precision cosmology
The scientific potential of the dataset is vast. Cosmological simulations are essential tools for interpreting observational data from next-generation telescopes and surveys. By comparing simulated universes with real observations, researchers can test competing models of:
- Dark matter particle properties
- Dark energy and cosmic acceleration
- Galaxy formation and evolution
- Large-scale structure statistics
FLAMINGO’s scale enables percent-level precision cosmology, allowing subtle deviations between theory and observation to be identified and explored.
Moreover, the ability to simulate rare, large-scale structures, such as massive galaxy clusters, provides insights that smaller simulations cannot capture. These structures serve as sensitive probes of cosmological parameters and fundamental physics.
Inspiring the next era of computational science
The release of this dataset is more than a technical achievement; it is a statement about the future of science. By making one of the largest supercomputer-generated datasets openly available, the team is lowering the barrier to entry for researchers, students, and institutions worldwide.
As noted by project leaders, access to facilities like COSMA-8 is typically limited. By distributing the results of these simulations globally, the project transforms a localized supercomputing capability into a shared scientific resource.
This approach reflects a broader trend: supercomputing is no longer just a tool; it is an infrastructure for collaboration and discovery.
Toward an exaflops cosmos
Looking ahead, projects like FLAMINGO foreshadow the coming era of exaflops computing, where simulations will achieve even higher resolution, incorporate additional physical processes, and integrate real-time observational data.
For now, Durham’s 2.5 petabytes universe stands as a powerful demonstration of what is possible when computational ambition meets scientific vision. It is a reminder that, in the age of supercomputing, humanity is no longer limited to observing the cosmos; we are beginning to recreate it.